이번 글에서는 백업을 구성한 과정을 이야기한다. 절반은 조금 더 진지한 블로그를 만들고 싶다는 마음에서, 절반은 내가 지어놓은 체계를 나중에 들여다보기 좋도록 하고자 쓴다.
배경
서버를 굴린다는 것은 데이터를 손에 쥐고 있다는 것. 가끔 힘이 빠지면 데이터를 놓친다. 좋은 소식은 데이터가 복사된다는 것. 복사해놓자. 놓쳤을 때 복사본을 다시 쥐자.
나는 프로그래머. 다른 말로 자동화 귀신이다. 복사를 자동화하자. 백업하자는 뜻이다.
백업 구성 1 - AWS
개인용 AWS 계정을 만들었다. 데이터를 내가 쥐고 있자는 취지에서 세운 아지트였지만 결국 대기업 인프라에 의존하게 되었다. 여전히 나도 쥐고 있으니 괜찮다고 치자.
AWS는 항상 모든 것을 복잡하게 만든다. 동아리를 열심히 해서 다행이다. 열심히 했어도 항상 헷갈리는데, 안 열심히 했으면 얼마나 헷갈렸을까. AWS는 항상 "더 안전한" 방법을 만든다. 예전에 쓰던 방법은 모두 폐기 권장(deprecated)하고 새로운 방법을 쓰라고 한다. 더 안전하겠거니 하고 따라해봤지만 내가 50개의 어플리케이션과 500개의 계정을 관리하는 사람이 아닌 이상 다 쓸데없는 짓이다. 덜 안전하고 단순한 방법을 쓰자.
AWS에서 사용하는 서비스는 두가지다. 먼저 맨 처음 제시된 문제인 백업을 풀어내기 위한 S3를 먼저 보고, 그 다음에 백업 작업을 스크립트로 하기 위해 필요한 IAM을 보자.
S3
S3는 Simple Storage Service의 약자로, 단순히 말하면 AWS 서버에 파일을 저장하는 서비스다. 데이터를 담을 통인 '버킷'을 여러개 만들고 각 버킷에 파일 여러개를 디렉토리로 정리하여 저장할 수 있다.
저장 비용은 GB당 월 0.025달러이고, 업로드 비용은 제로, 다운로드 비용은 GB당 0.09달러이다. 사용 구간별로 가격이 달라지지만 소규모로 쓸 때는 그러하다. 대충 아지트 백업 용량이 1GB라고 치면 달마다 30~40원 정도 나가는 것이니 부담이 가지는 않는다.
버킷 하나를 만들었고, 여기에는 매주 데이터베이스와 업로드 파일들이 백업된다. 데이터베이스는 데이터 손실이 치명적이기 때문에 매번 자료가 축적되도록 하고, 파일은 용량이 커질 것으로 예상하여 백업 시점의 스냅샷만 올리는 것으로 결정하였다.
특별한 설정은 하지 않았다. 원래는 버전 설정을 해볼까 했으나 업로드 파일들은 버전 관리를 하지 않을 예정이기 때문에 뺐다. 데이터베이스 백업 파일은 매번 하나의 .sql 스크립트로 저장되고 파일명은 "db-날짜.sql"의 형식을 따르도록 했다.
IAM
IAM은 Identity and Access Management의 약자다. IAM을 통해 CLI로 로그인할 계정을 생성할 수 있다. 반대로 말하면 IAM을 통해야만 CLI로 로그인이 가능하다. 예전에 동아리 세미나로 처음 AWS를 써볼 때 개고생했던 기억이 난다. 이번에도 "더욱더 안전한" 방법을 써보려고 이리저리 힘썼으나 다 부질없는 일임을 깨닫고 가장 간?단한 방법으로 틀었다. 혹시 "더욱더 안전한" 방법이 굳이 궁금하다면 IAM Identity Center를 참고하라.
아마 IAM은 비용이 별도로 안 들 것이다. 딱 그렇지 않고 그럴 것인 이유는 버스에서 쓰느라 멀미가 나서다.
가장 간단하다고는 하지만 여전히 AWS가 잘게 쪼개 정규화해놓은 스킴을 충실히 따랐다.
- 사용자(user)는 모임(user group)에 소속된다.
- 모임은 권한규칙(policy)을 따른다.
- 권한규칙은 할 수 있는 작업(action)에 대한 권한을 부여한다.
약간 복잡하지만 어렵지는 않다. "아지트관리자"라는 사용자는 "아지트백업하는모임"에 속해있다. "아지트백업하는모임"은 "S3쥐락펴락"이라는 권한규칙을 따른다. "S3쥐락펴락"은 이름 그대로 S3에 대한 모든 권한을 부여한다. 따라서 "아지트관리자"는 S3에 대한 모든 권한을 받았다.
"아지트관리자"로써 CLI에 로그인하기 위해서는 비밀번호 같은 게 필요하다. AWS는 언제 어디서나 로그인할 수 있는 비밀번호는 권장하지 않는다. 대신 접속키(access key)를 만들어 각 기기마다 서로 다른 접속키로 접속할 것을 권장한다. 아마 이렇게 하면 하나가 유출되도 모두에게 새 키를 돌릴 필요가 없어서 좋으려나? 이러나저러나 아지트 서버에서만 접속하고자 하는 내겐 쓸데없이 복잡한 정책이다. 그래도 습관 들이는 게 중요하겠지....
접속키는 IAM 사용자 항목 페이지에서 "Security Credentials" 탭의 "Access Keys" 섹션에서 발급할 수 있다. 이렇게 써놓아도 아마 내년쯤 AWS는 또다시 UI를 갈아엎을 것 같아서 무의미할 것 같다. 들어가면 다른 "더욱더욱더 안전한" 대안을 마구 제안하는데 혼자 만드는 아지트 관리할 때는 별 쓸데없는 조언이니 과감히 무시하기로 했다. 이것도 AWS의 UI 지맘대로 갈아엎어서 티스토리 찾아본 건 쓸데도 없고 아무도 제대로 쓸 수 없게 만들어서 대충 뉴비들 예스맨으로 몰아간 다음에 요금 폭탄 때리고서는 "하지만 안전했죠? 성능 겁나 좋아졌죠? 확장성 뒤지죠? 구글 메타 일론머스크 게섯거라죠? 한잔 하시고~ 네! 감사합니다."라고 입 싹 닫기 위한 큰 그림일 것을 생각하면 손이 덜덜 떨리고 온몸이 으슬으슬 소름이 돋고 식은땀이 흐른다. 뭐 어쨌든... 언제나 그랬듯 "응~ 보안 취약하면 니가 뭘할 수 있는데~"로 대응하면 될 뿐이고 접근키는 CSV 파일로 잘만 받아진다. Access key ID와 Secret access key 항목이 있는데 잘 뒀다가 나중에 CLI 로그인할 때 써먹으면 된다.
백업 구성 2 - 아지트
아지트에서 할 일은 두 가지다. 첫번째는 AWS CLI를 설치하고 아까 받은 접근키로 인증 설정하는 일, 두번째는 매주 백업 스크립트가 실행되서 백업이 이루어지도록 설정하는 일이다. 백업 스크립트는 AWS CLI를 통해 S3에 백업할 내용을 업로드하는 간단한 동작이고, 이를 systemd 타이머 유닛이라는 이번에 새로 알게 된 방법으로 설정하였다.
AWS CLI 설치 및 설정
이 부분은 AWS 문서를 잘 따르면 된다. 설치는 여기를 참고. 여기 적힌 명령어를 그대로 복사하여 실행했다.
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
다만 한가지 돌발상황은 unzip이 안 깔려있었다는 것인데 아치리눅스 같은 이상한 거 안 쓰는 한 다들 잘 깔려있겠지 싶다. 패키지 매니저로 금방 깔고 다시 실행하니 잘 되었다. 다 깐 후에 which aws 해보시라.
그 뒤에는 사실 문서 안 읽고 예전의 기억을 살려 aws configure 명령어를 바로 실행했다. 그럼 이렇게 나온다.
AWS Access Key ID [None]: asdf
AWS Secret Access Key [None]: qwer
Default region name [None]:
Default output format [None]:
아까 CSV 파일에 있던 내용으로 맨 앞의 두 값을 채우면 된다. region 값은 S3와 맞춰서 ap-northeast-2로 넣어주었다. 잘은 몰라도 대충 빠를 것이다.
설정이 끝난 후에는 테스트를 해본다. 나는 S3쥐락펴락이 되니까 aws s3 ls를 실행해봤다. 잘 된다. 이따 백업 스크립트는 루트 계정으로 실행해야 되기 때문에 sudo aws configure도 한번 해주었다.
백업 스크립트 작성
백업 스크립트 내용은 대략 다음과 같다:
docker compose exec db pg_dump | aws s3 cp - s3://bucket/db-$(date -Idate).sql
aws s3 sync upload s3://bucket/upload --delete
첫째줄은 도커에 올라가있는 코끼리SQL(postgresql) 내용을 덤프 떠서 S3에 db-2024-09-18.sql 꼴의 파일로 업로드한다. pg_dump는 코끼리SQL에서 제공하는 덤프 툴이다. 로컬 개발용 DB에 실제 DB 내용을 입힐 때 자주 써먹는다. 시스템 프로그래밍에서 배운 파이프는 여기서도 유용하다. pg_dump의 출력내용을 그대로 aws 명령어로 전달한다.
둘째줄은 파일 시스템에 있는 업로드 파일 구조를 그대로 S3에 올린다. 별로 설명할 내용이 없다. 매뉴얼에 있는 내용을 친절하게 읊자면(RTFM):
디렉토리와 S3 prefix를 맞춘다(sync). 출발 디렉토리의 새 파일이나 바뀐 파일들을 재귀적으로 도착지에 복사한다. 파일이 들어있는 디렉토리만 복사함에 주의. --delete : 도착지에 있지만 출발지에 없는 파일은 맞추는 과정에서 지운다.
chmod +x하여 스크립트 권한을 설정한 뒤 sudo로 실행해본다. 잘 된다. docker 명령어가 루트 권한으로만 실행되기 때문에 sudo로 해줘야 한다.
타이머 설정
이제 백업 스크립트가 주기적으로 실행되도록 할 차례. cron을 쓰면 간단하지만 아치리눅스에는 기본으로 깔려있지가 않다. 어차피 cron 쓰는 법도 찾아봐야하기 때문에 아치위키켜라! 알고보니 cron은 한 가지 바이너리를 다같이 쓰는 그런 권위적인 툴이 아닌 모양이다. 여러 구현이 있고 뭘 설치할지 고민하는 와중에 기본으로 깔려있는 Systemd/Timers를 쓰면 된다는 문구를 발견! 아는 툴의 새로운 기능을 배우는 것은 참을 수 없어~ 바로 알아본다.
systemd가 뭔지도 설명해야 할 것 같지만 그 이야기는 다시 한도끝도없이 길어질것만 같다. 운영체제 정도 수강한 사람이 알아들을 수 있게 말하자면, PID가 1인 일종의 init 프로세스로써 리눅스 시스템의 백그라운드 서비스들을 관리한다.
일반적인 systemd 서비스와 달리 타이머는 서비스 파일과 타이머 파일, 이렇게 두 개의 파일로 구성된다. 서비스 파일에는 실행한 작업에 대한 내용이 들어가고, 타이머 파일에는 실행 계획에 대한 내용이 들어간다. 이 파일들을 또 어디 놓아야 잘 놓았다고 소문이 날까 고민을 해보았는데, 어느 유저에 종속되는 건 아니니 시스템 서비스이고, 내가 직접 써서 넣어놓는 파일이니까 /etc/systemd/system에 넣으면 된다. 결국 맨날 넣는 그 자리다. 맨페이지(manpage)에 이런 표도 있다.

확장자만 name.service와 name.timer로 다르게 해서 여기에 파일을 넣어놓고 systemctl enable name.timer; systemctl start name.timer 이렇게 해놓으면 타이머 설정이 된다. 서비스 파일은 이렇게 썼다:
[Unit]
Description=Backup freleefty agit
[Service]
Type=oneshot
ExecStart=/path/to/script.sh
이 서비스는 딱 한번 실행하면 바로 끝나는 유형이며(Type=oneshot) 그 실행은 저깄는 스크립트(ExecStart)로 하라는 뜻이다. 타이머 파일은 이렇다:
[Unit]
Description=Run blog-backup weekly
[Timer]
OnCalendar=weekly
Persistent=true
[Install]
WantedBy=timers.target
매주 실행되며(OnCalendar=weekly), 혹시 마지막으로 설정한 때에 실행을 못했으면 당장 실행하라는 뜻(Persistent=true)이다. 어떤 녀석을 실행하냐, 하는 것은 위에서 말했듯 타이머와 서비스 파일명을 같게 해서 설정한다. 컨벤션이 아니라 기능이다~.
잘 설정이 됐는지는 systemctl list-timers로 확인할 수 있다. 옆으로 길어서 안 예쁜 표가 나온다.
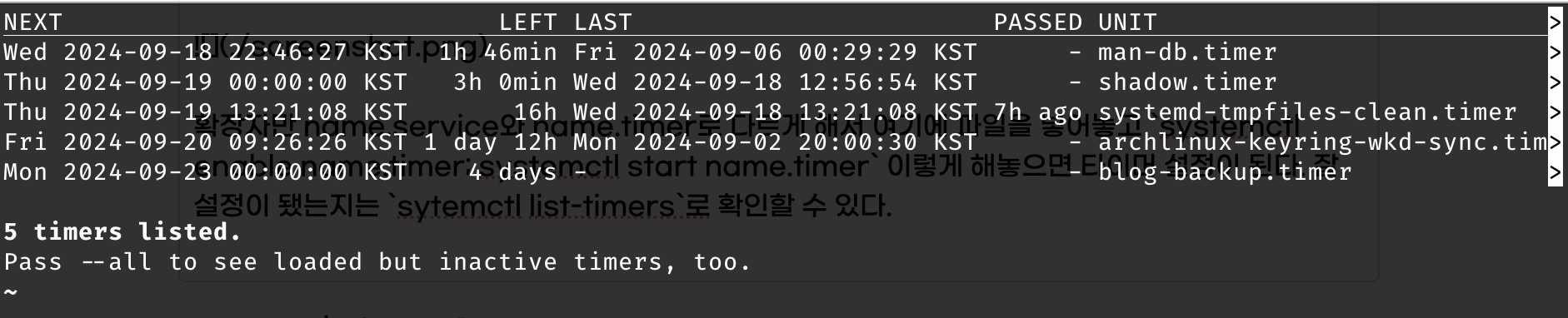
이제 아마 백업이 될 것이다. 다음주 월요일에 확인해볼 수 있을 것.
마무리
음~ 무슨 얘기를 할까~ 생각 외로 길어졌다. 오늘의 교훈. 항상 성능/보안/확장성 같은 말에 목 매지 말 것. 언제나 적당히 잘 되는 것을 골라야 한다. 내가 모든 것의 신이 아니다. 모든 자본의 독점자도 아니다.... 또 하나의 교훈이 있다면 아치위키는 언제나 공부가 된다는 것? systemd 타이머를 배웠다. 아치위키 켜라~